Imagine typing a script and hearing it played back in a voice so lifelike you’d swear a human recorded it. That’s neural TTS at work — and it’s reshaping how we interact with machines, consume content, and experience the world.

// simulated neural TTS audio waveform
Neural TTS, or neural text-to-speech, is an AI-driven TTS technology that uses neural networks in audio processing to convert written text into strikingly natural-sounding speech. Unlike the robotic, monotone voices of older systems, neural TTS produces intonation, rhythm, and emotion that feel genuinely human.
Traditional TTS systems stitched together pre-recorded phonemes or used rigid rule-based formulas — the result was speech that was technically intelligible but emotionally flat. The leap to deep learning TTS changed everything. Models now learn directly from thousands of hours of human voice recordings, internalizing the subtle patterns of pitch, pace, and pause that make speech feel alive.
70% Virtual assistants powered by neural TTSPlatforms like Amazon Alexa, Google Assistant, and Apple Siri now rely heavily on neural TTS pipelines to deliver conversational, context-aware responses at scale.
In this guide, you’ll get a complete picture of neural TTS — from its core building blocks and inner workings, to the most powerful open-source models available today, and the real-world applications reshaping industries from publishing to healthcare. Let’s dive in.
Neural TTS Explained: From Basics to Core Components
What Makes Neural TTS Different from Traditional TTS?
The easiest way to understand neural TTS is to compare it to its predecessors. Rule-based TTS systems, also called concatenative synthesis, work by splicing together audio fragments. The output sounds passable but mechanical. Neural TTS, by contrast, doesn’t stitch — it generates. The entire acoustic output is synthesized from scratch using learned representations.
| Feature | Rule-Based TTS | Neural TTS |
|---|---|---|
| Naturalness | Low — robotic, monotone | High — human-like prosody |
| Flexibility | Rigid phoneme rules | Learns from raw audio data |
| Emotion & Tone | Minimal or scripted | Supports emotional TTS, dialects |
| Training Data | Hand-crafted rules | Hours of recorded speech |
| Compute Cost | Low | Higher (GPU-intensive) |
| Use Cases | Legacy IVR, basic readers | Assistants, audiobooks, voice cloning |
Key Building Blocks of Neural TTS Systems
A complete neural TTS pipeline typically consists of four major modules working in sequence:
- Text Analyzer — Normalizes input text, handles abbreviations, numbers, and special characters, and converts text to phoneme sequences.
- Acoustic Model — The brain of the system. Models like Tacotron map phoneme sequences to mel spectrograms (a visual representation of audio frequencies over time).
- Vocoder Models — Convert spectrograms to actual audio waveforms. WaveNet was a groundbreaking early vocoder; modern alternatives like HiFi-GAN and WaveGlow are much faster.
- Prosody Modeling Layer — Adds expressiveness: pitch curves, emphasis, pauses, and pacing. This is where emotional TTS and speaker style live.
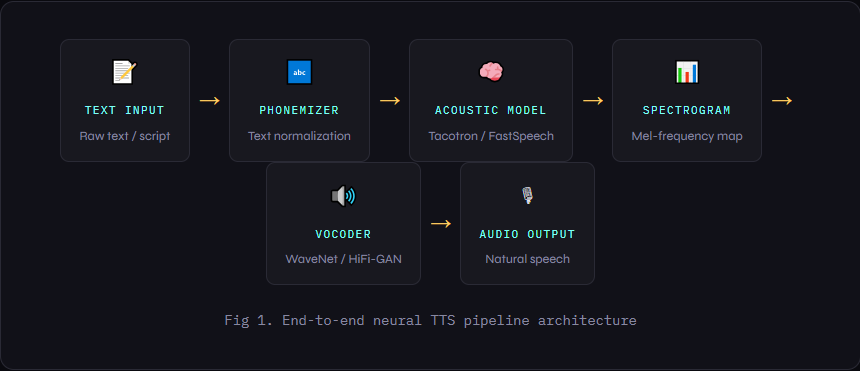
Fig 1. End-to-end neural TTS pipeline architecture
How Neural TTS Works: A Step-by-Step Breakdown
Understanding the end-to-end TTS pipeline demystifies a lot of the magic. Here’s what happens from the moment you feed text into a neural TTS system to the moment audio comes out.
- Text Preprocessing & NormalizationRaw text is cleaned and standardized. Numbers are expanded (“42” → “forty-two”), abbreviations resolved, and punctuation mapped to prosodic cues. The text is then converted to phoneme sequences using a grapheme-to-phoneme (G2P) model or a pronunciation dictionary.
- Sequence-to-Sequence ModelingThe phoneme sequence is fed into an acoustic model.Tacotron-stylearchitectures use an encoder-decoder structure with attention mechanisms to align input phonemes with output acoustic features — essentially learning what each sound “should look like” in frequency space.
- Spectrogram GenerationThe acoustic model outputs amel spectrogram— a 2D heatmap where the x-axis is time and the y-axis is frequency. This intermediate representation captures all the tonal and temporal qualities of the target speech without yet being audio.
- Real-Time Voice Generation via VocoderThe vocoder model converts the spectrogram back into raw audio waveforms. Early vocoders likeWaveNetwere autoregressive — generating one sample at a time — making them slow. Modern parallel vocoders like HiFi-GAN enablereal-time voice generationat low latency.
- Post-Processing for Emotion & StyleOptional conditioning layers can apply speaker identity, emotional tone, speaking rate, or accent. This is howvoice cloningworks — by injecting a target speaker’s embedding into the generation process. Style transfer andmultilingual TTSare handled here too.
“Think of a neural TTS system like a jazz band. The text is the sheet music. The acoustic model is the arranger who interprets tempo and feeling. The vocoder is the musicians who transform those instructions into live, breathing sound — improvising along the way.”— analogy for end-to-end TTS architecture
This AI voice synthesis pipeline — once requiring hours of compute — can now run in under 50 milliseconds on modern inference hardware, enabling truly low-latency TTS for real-time applications like live call agents and interactive games.
Popular Neural TTS Models and Tools
Pioneers: WaveNet and Tacotron
The story of modern speech synthesis models begins with two landmark papers from Google DeepMind and Google Brain.
WaveNet (2016) was the first neural vocoder to generate audio waveforms directly using dilated causal convolutions. It produced strikingly natural audio but was computationally slow due to its autoregressive sampling process — each audio sample was generated one by one. It remains the conceptual grandfather of modern neural audio.
Tacotron 2 (2017) closed the loop on the full pipeline by pairing a sequence-to-sequence acoustic model with a WaveNet vocoder. The result was the first truly end-to-end TTS system capable of converting raw text into natural speech with near-human quality. Tacotron introduced mel spectrogram prediction and attention alignment that remains foundational in today’s architectures.
Modern Open-Source Options
The open-source TTS ecosystem has exploded since 2020. Here are the most production-ready options available today:
| Model | Key Strength | Best Use Case | Multilingual? |
|---|---|---|---|
| Coqui TTS | Fast, easy to fine-tune | Voice cloning, edge deployment | ✅ 15+ languages |
| Mozilla TTS | Research-friendly, modular | Custom voice projects | ✅ Partial |
| Tortoise TTS | Exceptional quality | Audiobooks, narration | ❌ English primary |
| FastSpeech 2 | Low-latency TTS, parallel | Real-time applications | ✅ Yes |
| XTTS v2 | Zero-shot voice cloning | Personalized AI assistants | ✅ 16 languages |
For production low-latency TTS, FastSpeech 2 and its derivatives dominate. For voice cloning quality, Tortoise TTS and XTTS v2 lead the pack. And for multilingual deployments, Coqui’s multilingual XTTS models cover the broadest range of languages with consistent quality.
Real-World TTS Applications and Benefits
Neural TTS isn’t a research curiosity — it’s already embedded in products you use every day. Here’s where TTS applications are making the biggest impact:
- Accessibility — Screen readers powered by neural TTS give visually impaired users a far more natural experience, reducing cognitive fatigue from robotic speech.
- Audiobook & Podcast Production — Publishers use neural TTS to generate audiobook drafts in hours instead of weeks, with human narrators refining final outputs.
- Customer Service Automation — IVR systems and chatbots use emotional TTS to match tone to context — calm and empathetic for complaints, upbeat for sales.
- Gaming & Interactive Media — Dynamic NPC dialogue generated at runtime using voice cloning means infinite variations without re-recording sessions.
- E-Learning & Language Education — Multilingual TTS models produce pronunciation guides and lesson audio in dozens of languages from a single text source.
- Healthcare — AAC (augmentative and alternative communication) devices restore personalized voices to patients who have lost the ability to speak.
✦ Advantages
- Hyper-realistic, natural-sounding speech
- Customizable voice style & emotion
- Scales to millions of outputs instantly
- Supports voice cloning from short samples
- Multilingual without re-training
✦ Limitations
- GPU-intensive training & inference
- Bias from training data (accents, gender)
- Deepfake & impersonation risks
- High quality requires large datasets
- Licensing complexity for voice cloning
Challenges, Limitations, and the Future of Neural TTS
Despite its impressive capabilities, neural TTS still faces real-world hurdles. The most persistent is training data bias. Models trained predominantly on American English speakers often underperform for accented speech, non-standard dialects, or tonal languages like Mandarin or Yoruba — a significant equity concern.
Compute demands remain a barrier for smaller organizations. Running high-quality inference requires modern GPU infrastructure, and fine-tuning a voice model from scratch can cost thousands of dollars in cloud compute. Quantization techniques and mobile-optimized architectures are making progress, but the gap between research demos and edge deployment is still wide.
The deepfake problem is perhaps the most urgent ethical challenge. Voice cloning technology capable of mimicking anyone’s voice from a 30-second sample exists today. The industry is responding with audio watermarking standards, detection models, and regulatory frameworks — but it remains an active arms race.
Looking ahead, the future of neural TTS is fast, expressive, and personalized. Expect sub-10ms real-time latency on-device, emotion-aware generation that adapts dynamically to conversation context, and zero-shot multilingual models that speak any of 100+ languages without fine-tuning. The line between AI voice synthesis and a human recording will effectively disappear.
Conclusion: Neural TTS Is Rewriting the Voice of AI
From its roots in WaveNet and Tacotron to today’s zero-shot voice cloning models, neural TTS has undergone a transformation in under a decade. What was once a party trick — “hey, this doesn’t sound completely robotic!” — is now the backbone of billion-dollar products and life-changing accessibility tools.
The core insight remains powerful: by training deep neural networks directly on human speech, we’ve taught machines not just to pronounce words, but to speak. The implications for AI voice synthesis, content creation, healthcare, and education are still unfolding.
Whether you’re a developer integrating TTS into an app, a creator building a synthetic media pipeline, or simply curious about where AI is headed — neural TTS is one of the most tangible, immediately useful frontiers in AI today. Try a live demo, explore an open-source model like Coqui TTS, and hear the future for yourself.
Stay Ahead of the AI Voice Curve
Get our weekly digest of neural TTS research, tool releases, and industry applications — delivered to your inbox.Subscribe →
Frequently Asked Questions
What is neural TTS used for?
Neural TTS (neural text-to-speech) is used across accessibility tools like screen readers, audiobook and podcast production, virtual assistants, customer service chatbots, gaming NPC dialogue, and e-learning platforms. Any application requiring natural-sounding speech synthesis can benefit from neural TTS technology.
How is neural TTS different from traditional text-to-speech?
Traditional TTS uses rule-based or concatenative methods that stitch pre-recorded audio fragments, producing robotic-sounding output. Neural TTS uses deep learning models (like Tacotron and WaveNet) to generate audio end-to-end from learned data, producing natural-sounding speech with realistic prosody, emotion, and rhythm.
What are the best open-source neural TTS tools in 2026?
Top open-source TTS tools include Coqui TTS (multilingual, great for voice cloning), Tortoise TTS (exceptional quality for narration), FastSpeech 2 (low-latency TTS for real-time apps), and XTTS v2 (zero-shot voice cloning across 16 languages). Mozilla TTS is also widely used for research applications.
Can neural TTS clone any voice?
Modern voice cloning models like XTTS v2 and Tortoise TTS can replicate a speaker’s voice from as little as 6–30 seconds of audio with impressive accuracy. However, cloning a voice without consent raises serious ethical and legal concerns, and many platforms are implementing watermarking and usage policies to prevent abuse.
What is prosody modeling in neural TTS?
Prosody modeling refers to the component of a neural TTS system that controls the expressive qualities of speech — including pitch, stress, rhythm, speaking rate, and pause duration. It’s what gives neural TTS its human-like intonation and makes emotional TTS possible, allowing systems to sound calm, excited, empathetic, or authoritative depending on context.